Weil Sie wissen das Deep learning / Maschinelles Lernen eine komplexe Sache ist,
und als größeres Unternehmen den Zug trotzdem nicht verpassen möchten,
haben Sie die Erkenntnis dass Sie einen Erfahrenen Partner brauchen.
Für eine Terminvereinbarung, bitten wir Sie 1.190 € an folgende Adresse zu überweisen.
XiLLeR GmbH
IBAN: DE42 7602 0070 0358 9905 84
BIC: HYVEDEMM460
Verwendungszweck: Telefonnummer und Ihren Namen.
Sie erhalten eine Rechnung. Bitte Kontaktieren Sie uns nur, wenn Ihnen
bewusst ist, dass das Vorhaben mehr als 170.000€ beanspruchen wird.
In den 1.000€ Netto sind 2 Std. Telefon/Video Beratung inklusiv.
In nur 2 Stunden ist es oft geklärt ob ein Projekt überhaupt stattfinden sollte oder nicht. Statt viel Zeit & Ressourcen zu investieren,
haben Sie hier die Chance viel Lehrgeld zu sparen.
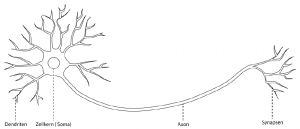 Abbildung 2.1: Aufbau eines biologischen NeuronsEin Nervensystem (neuronales Netz) besteht aus Nervenzellen, Neuronen genannt. Die Verbindung von Neuron zu Neuron wird über die sogenannten Dendriten hergestellt. Diese nehmen ein ihnen übergebenes Signal auf und leiten es weiter zum Zellkern (Soma). Da ein Neuron mehrere Dendriten besitzen kann, trefen im Soma auch mehrere Signale zusammen. Diese werden dann aufaddiert, und falls das Ergebnis (Erregung) einen bestimmten Schwellwert überschreitet, wird das Neuron „aktiviert“. Es entsteht eineaktive elektrische Welle, die über das Axon zu den Synapsen weitergeleitet wird. So wird der Reiz an die Nachbarzelle(n) gereicht
Abbildung 2.1: Aufbau eines biologischen NeuronsEin Nervensystem (neuronales Netz) besteht aus Nervenzellen, Neuronen genannt. Die Verbindung von Neuron zu Neuron wird über die sogenannten Dendriten hergestellt. Diese nehmen ein ihnen übergebenes Signal auf und leiten es weiter zum Zellkern (Soma). Da ein Neuron mehrere Dendriten besitzen kann, trefen im Soma auch mehrere Signale zusammen. Diese werden dann aufaddiert, und falls das Ergebnis (Erregung) einen bestimmten Schwellwert überschreitet, wird das Neuron „aktiviert“. Es entsteht eineaktive elektrische Welle, die über das Axon zu den Synapsen weitergeleitet wird. So wird der Reiz an die Nachbarzelle(n) gereicht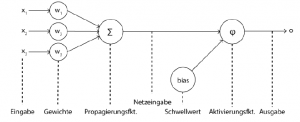 Abbildung 2.2: Aufbau eines künstlichen Neurons Um dies nun auf ein künstliches Prinzip umzumünzen, wird zunächst auch eine Recheneinheit erstellt, die ein künstliches Neuron darstellt (siehe Abb.2.2) Es wurden verschiedene künstliche Neuronen geschaffen, die sich in der Handhabung der ihnen übergebenen Daten unterscheiden. Im Grundaufbau sind sie aber vergleichbar. Ein künstlichesNeuron nimmt eine oder mehrere Informationen als gewichtete Eingangswertean und generiert daraus einen Wert, den es dann über eine gerichtete und gewichtete Verbindung weiterreicht. Das Gewicht wirkt sich verstärkend bzw. hemmend auf die Erregung aus. Auch ein künstliches Neuron besitzt eine Systematik (Aktivierungsfunktion) mit der es entscheidet, ob der Wert das Neuron aktiviert oder nicht. Dabei spielt der Schwellwert eine große Rolle [Nie15].In diesem Kapitel wird lediglich das Grundprinzip von künstlichen Neuronen erläutert.Auf ihren mathematischen Ansatz wird in Kapitel 2.4 genauer eingegangen.Im Detail besteht die Verarbeitung einer Eingabe durch ein künstliches Neuron laut Kriesel [Kri07, S. 9f] aus folgenden Schritten:
Abbildung 2.2: Aufbau eines künstlichen Neurons Um dies nun auf ein künstliches Prinzip umzumünzen, wird zunächst auch eine Recheneinheit erstellt, die ein künstliches Neuron darstellt (siehe Abb.2.2) Es wurden verschiedene künstliche Neuronen geschaffen, die sich in der Handhabung der ihnen übergebenen Daten unterscheiden. Im Grundaufbau sind sie aber vergleichbar. Ein künstlichesNeuron nimmt eine oder mehrere Informationen als gewichtete Eingangswertean und generiert daraus einen Wert, den es dann über eine gerichtete und gewichtete Verbindung weiterreicht. Das Gewicht wirkt sich verstärkend bzw. hemmend auf die Erregung aus. Auch ein künstliches Neuron besitzt eine Systematik (Aktivierungsfunktion) mit der es entscheidet, ob der Wert das Neuron aktiviert oder nicht. Dabei spielt der Schwellwert eine große Rolle [Nie15].In diesem Kapitel wird lediglich das Grundprinzip von künstlichen Neuronen erläutert.Auf ihren mathematischen Ansatz wird in Kapitel 2.4 genauer eingegangen.Im Detail besteht die Verarbeitung einer Eingabe durch ein künstliches Neuron laut Kriesel [Kri07, S. 9f] aus folgenden Schritten: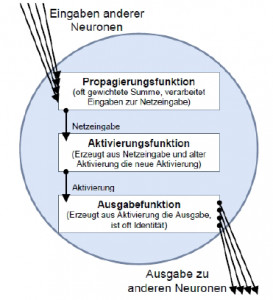 Abbildung 2.3: Verarbeitungsschritte einer Neuroneneingabe
Abbildung 2.3: Verarbeitungsschritte einer Neuroneneingabe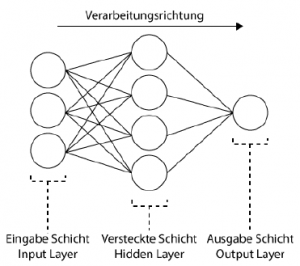 Abbildung 2.4: Schichten eines künstlichen neuronalen NetzesEin KNN hat verschiedene Arten von Schichten (Layers). Wie in Abb. 2.4 zu sehen, nennt man die erste Schicht das Input Layer. Ihm werden üblicherweise die eingespeisten Werte lediglich übergeben. Die letzte Schicht ist das Output Layer. Es klassiiziert nun die ihm übergebene Problematik. Zwischen Input- und Output Layer liegen die sogenannten Hidden Layers von unterschiedlicher Anzahl, jedoch mindestens eine. Je komplexer ein Netzwerk ist, desto mehr Hidden Layer besitzt es.2.3.3 Feedforward NetzFeedForward Netze haben eine klare Schichtung. Das bedeutet, es gibt eine Eingabeschicht, beliebig viele folgende versteckte Schichten und eine Ausgabeschicht. Die Verbindungen zwischen Neuronen gehen ausschließlich von einem Neuron einer Schicht zu Neuronen der nächstfolgenden Schicht, die in Richtung Ausgangsschicht liegt. In FeedForward Netzen ist es üblich, dass ein Neuron alle Neuronen der nächsten Schicht bedient. Das bedeutet, die Schichten sind untereinander vollverknüpft.
Abbildung 2.4: Schichten eines künstlichen neuronalen NetzesEin KNN hat verschiedene Arten von Schichten (Layers). Wie in Abb. 2.4 zu sehen, nennt man die erste Schicht das Input Layer. Ihm werden üblicherweise die eingespeisten Werte lediglich übergeben. Die letzte Schicht ist das Output Layer. Es klassiiziert nun die ihm übergebene Problematik. Zwischen Input- und Output Layer liegen die sogenannten Hidden Layers von unterschiedlicher Anzahl, jedoch mindestens eine. Je komplexer ein Netzwerk ist, desto mehr Hidden Layer besitzt es.2.3.3 Feedforward NetzFeedForward Netze haben eine klare Schichtung. Das bedeutet, es gibt eine Eingabeschicht, beliebig viele folgende versteckte Schichten und eine Ausgabeschicht. Die Verbindungen zwischen Neuronen gehen ausschließlich von einem Neuron einer Schicht zu Neuronen der nächstfolgenden Schicht, die in Richtung Ausgangsschicht liegt. In FeedForward Netzen ist es üblich, dass ein Neuron alle Neuronen der nächsten Schicht bedient. Das bedeutet, die Schichten sind untereinander vollverknüpft.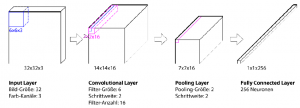 Abbildung 2.5: Schichten eines Convolutional Neural NetworksWenn ein Bild durch ein neuronales Netzwerk verarbeitet wird, muss man davon ausgehen, dass der interessante Blickpunkt nicht zwangsläuig im Zentrum des Bildes sein muss. Das Netzwerk sollte das gesuchte Objekt überall im Bild inden. Um einem Netzwerk beizubringen, ein Objekt zu erkennen, unabhängig davon, wo es sich im Bild beindet, braucht man eine bestimmte Art der Bild(vor)verarbeitung, die „Convolution“ (Konvolution) genannt wird.Ein klassisches CNN hat bestimmte Schichten, die nun mit einem konkreten Beispiel (Abb. 2.5) erklärt werden. Als Input ist ein Bildformat von 32×32 Pixeln mit 3 Kanälen (RGB) gegeben.
Abbildung 2.5: Schichten eines Convolutional Neural NetworksWenn ein Bild durch ein neuronales Netzwerk verarbeitet wird, muss man davon ausgehen, dass der interessante Blickpunkt nicht zwangsläuig im Zentrum des Bildes sein muss. Das Netzwerk sollte das gesuchte Objekt überall im Bild inden. Um einem Netzwerk beizubringen, ein Objekt zu erkennen, unabhängig davon, wo es sich im Bild beindet, braucht man eine bestimmte Art der Bild(vor)verarbeitung, die „Convolution“ (Konvolution) genannt wird.Ein klassisches CNN hat bestimmte Schichten, die nun mit einem konkreten Beispiel (Abb. 2.5) erklärt werden. Als Input ist ein Bildformat von 32×32 Pixeln mit 3 Kanälen (RGB) gegeben.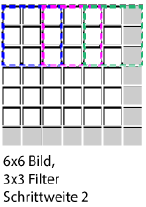 Abbildung 2.6: Zero- PaddingPadding kann aber auch zu einem anderen Zweck benutzt werden: Durch Konvolution wird die Output-Größe immer kleiner. Um diese schrittweise Verkleinerung abzuschwächen, wird oft auch Padding eingesetzt.Da es Sinn macht, einen Filter, der ein Merkmal repräsentiert, für jeden Bildausschnitt gleich zu gewichten, teilen sich die Neuronen einen Gewichtswert. Man spricht von geteilten Gewichten (Shared Weights)[Wikb].
Abbildung 2.6: Zero- PaddingPadding kann aber auch zu einem anderen Zweck benutzt werden: Durch Konvolution wird die Output-Größe immer kleiner. Um diese schrittweise Verkleinerung abzuschwächen, wird oft auch Padding eingesetzt.Da es Sinn macht, einen Filter, der ein Merkmal repräsentiert, für jeden Bildausschnitt gleich zu gewichten, teilen sich die Neuronen einen Gewichtswert. Man spricht von geteilten Gewichten (Shared Weights)[Wikb]. Abbildung 2.7: Durch Deconvolution visualisierte Filtermerkmale eines CNNs [ZF13]
Abbildung 2.7: Durch Deconvolution visualisierte Filtermerkmale eines CNNs [ZF13]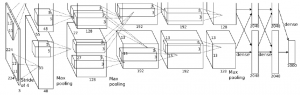 Abbildung 2.8: Architektur des CNN AlexNet [KSH12] 2.5.2.2 VGG NetVGG Net wurde 2014 entwickelt [SZ14]. Mit einer Fehlerrate von 7,3% bauten KarenSimonyan und Andrew Zisserman ein zwar einfaches, aber tiefes Netz.VGG Net ist eines der einlussreichsten Netze, da es ausdrücklich betont, das CNNstiefe Schichten haben müssen, damit sie funktionieren können.
Abbildung 2.8: Architektur des CNN AlexNet [KSH12] 2.5.2.2 VGG NetVGG Net wurde 2014 entwickelt [SZ14]. Mit einer Fehlerrate von 7,3% bauten KarenSimonyan und Andrew Zisserman ein zwar einfaches, aber tiefes Netz.VGG Net ist eines der einlussreichsten Netze, da es ausdrücklich betont, das CNNstiefe Schichten haben müssen, damit sie funktionieren können.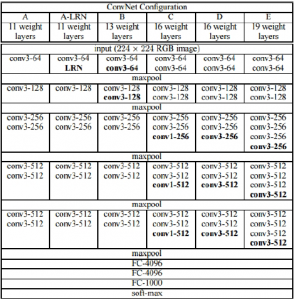 Abbildung 2.9: Architekturen des CNN VGG mit D als erfolgreichstes Netz[SZ14]
Abbildung 2.9: Architekturen des CNN VGG mit D als erfolgreichstes Netz[SZ14]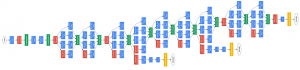 Abbildung 2.10: GoogleNet Architektur [Sze+15]2.5.2.4 Microsoft ResNetMicrosoft ResNet [Gir+13], erstellt von Microsoft Research Asia, gewann 2015 die ILSVRC mit einer Fehlerrate von 3,6%. Es hat 152 Schichten und setzt neue Maßstäbe in Bezug auf Klassiikation, Erkennung und Lokalisierung.
Abbildung 2.10: GoogleNet Architektur [Sze+15]2.5.2.4 Microsoft ResNetMicrosoft ResNet [Gir+13], erstellt von Microsoft Research Asia, gewann 2015 die ILSVRC mit einer Fehlerrate von 3,6%. Es hat 152 Schichten und setzt neue Maßstäbe in Bezug auf Klassiikation, Erkennung und Lokalisierung.  Abbildung 2.12: Prinzip eines R-CNN [Gir+13]2.5.3 Aktueller Stand (Jan. 2017)Große Bilder-Datenbanken, die als Input für das Training herangezogen werden können, sind sehr attraktiv für das Arbeiten mit CNN (näheres im Kapitel 3.1). Im Laufe der Zeit entstanden große Datensätze und Bestehende wurde erweitert. Dies und Optimierungen von Graikkarten und der Hardware im Allgemeinen hat die Forschung schnell vorangetrieben. Der Trend geht zu immer tieferen CNNs, die große Trainingsdatensätze verlangen und hohe Rechenpower wurde möglich durch eben diese Entwicklungen [Gu+15]Laut [LKJ16] geht der Trend von CNN geht über zu kleineren Filtern. Außerdem wird mit Topologien experimentiert, die gänzlich auf Pooling- und Fully-Connected-Schichten verzichten und sie durch Konvolutionsschichten ersetzen.
Abbildung 2.12: Prinzip eines R-CNN [Gir+13]2.5.3 Aktueller Stand (Jan. 2017)Große Bilder-Datenbanken, die als Input für das Training herangezogen werden können, sind sehr attraktiv für das Arbeiten mit CNN (näheres im Kapitel 3.1). Im Laufe der Zeit entstanden große Datensätze und Bestehende wurde erweitert. Dies und Optimierungen von Graikkarten und der Hardware im Allgemeinen hat die Forschung schnell vorangetrieben. Der Trend geht zu immer tieferen CNNs, die große Trainingsdatensätze verlangen und hohe Rechenpower wurde möglich durch eben diese Entwicklungen [Gu+15]Laut [LKJ16] geht der Trend von CNN geht über zu kleineren Filtern. Außerdem wird mit Topologien experimentiert, die gänzlich auf Pooling- und Fully-Connected-Schichten verzichten und sie durch Konvolutionsschichten ersetzen.